|
You have the choice of only one, a couple or all subscriber lists. You may determine separately the 'Match Fields' – for example, surname, email address, company etc. Often the matching is started by only balancing the field 'Email'. As an example, it is possible that there are more than one entries of the email address info@MAILINGWORK.de due to multiple contact persons. In the case, MAILINGWORK detects these multiple entries; you can start another search considering email address and surname. In fact, this is an easy way to filter duplicates, and you do not accidentally delete still needed data records. Another possibility would be to match the fields 'Email' and – if existing – 'Customer's ID'.
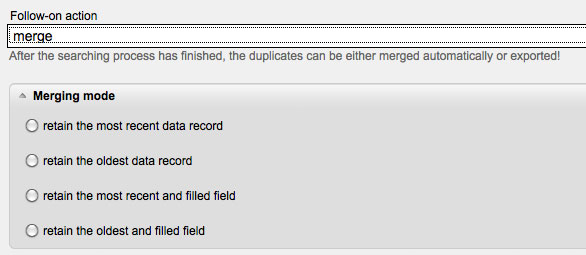
Under 'Follow-on Action' you may either choose between 'Merge' or 'Export'. In the case you did not choose any follow-on action, you will first get to the search results page and then you can decide how to continue. 'Export' creates a CSV file, which you can save on your computer and edit manually. 'Merge' merges the data records according to the selected options. The 'Merging Options' are the following:
|
|
Retain the most recent data record: Older data records will be deleted, the most recent one retains.
Retain the oldest data record: The first created data record retains, all newer ones will be removed.
Retain the most recent and filled field: MAILINGWORK searches the duplicate data records for the most recent subscriber fields and merges their data records. Even with fields with multiple choices the most recent data still exists. If a field is only filled in an older data record, this information will be copied to the most recent one.
Retain the oldest and filled field: All duplicate data records are searched for the oldest subscriber fields and merged to a combined data record.
The oldest subscriber ID remains when doing a duplicate matching. The activities belonging to this ID remain; activities belonging to other IDs, however, don't. When matching more than one list, the subscriber is matched only once to the system and, at the same time, separately to all selected lists. This becomes important if you want to send an email to multiple lists at once.
The automatic link tracking in the body works as well as in the HTML part. However, it should be noted that the link URLs are exactly visible. Because of a diversion via the server, the URLs will change. You can check its accuracy by sending a test mailing. Decide on whether you want to adjust the tracking link or not.
By clicking on 'Start', MAILINGWORK starts with the duplicate matching and changes to the tab 'Search results'. Show a little patience at this point. Depending on the number of subscribers and the match fields, it may take some time to finish the matching. Having finished, you will be shown the amount of 'Duplicates' and 'Groups'. If you only compare the email addresses and there are, for example, three entries with the email info@MAILINGWORK – all belonging to different contact persons –, MAILINGWORK will still recognize the entries as duplicates in spite of the different contact persons. The result would be that these three entries would be shown as three duplicates of the group info@MAILINGWORK.de.
At this point, following actions are available: 'Results', 'Merge', 'Export' and 'Delete'. 'Delete' removes the selected subscribers. 'Export' creates a CSV file which you can save on your computer and, for example, access or edit via Excel. 'Merge' shows the listed merging options from above and transfers the duplicates according to your choice into a data record.
By clicking on results you get a detailed view of the detected duplicates.
One click on the trash can icon quits the search. The tab 'Merge' and 'Export' both show you the current status of the chosen actions in the duplicate search.
|